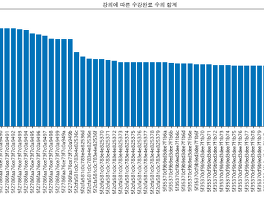
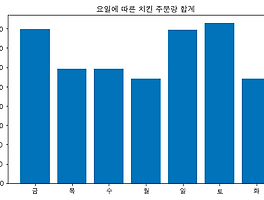
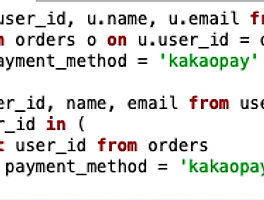
전체 글 (20) 썸네일형 리스트형 데이터 분석1-2. 이탈 분석 1. 목적 스파르타 코딩 클럽 A강의에서 수강생이 이탈하는 지점은 어디일까? 개인적으로는 2주차를 끝내고, 3주차 강의를 시작하기가 어려웠는데, 과연 데이터는 어떨지 궁금하다. 2. 준비: 강의별 유저수 합계 지난주와 동일하지만, 손에 익숙해 질 수 있도록 계속 입력해본다. 데이터를 불러오고 import pandas as pd enroll = pd.read_csv('./data/enrolleds_detail.csv') 강의별 유저수 합계가 필요하므로 enroll_detail = enroll.groupby('lecture_id')['user_id'].count() 그래프를 그려서 눈에 띄는 지점이 있는지 살펴본다. import matplotlib.pyplot as plt plt.rcParams['font... 데이터 분석 1-1. 상권 분석 1. 목적 첫 번째로는 특정 지역(서울)에서 치킨집이 가장 많이 분포하는 곳을 찾아내고, 추가로 의미 있는 데이터가 있을지 살펴보고 분석할 예정이다. 2. 준비: 지역 구분 데이터를 분석하기 전에는 항상 목적(무엇을, 어떻게, 왜 살펴볼 것인지)이 명확하게 정하고 난 다음, 데이터를 불러오고 import.pandas as pd commercial = pd.read_csv('./data/commercial.csv') commerical 데이터를 살펴보고 commercial.tail(5) list(commercial), len(list(commercial)) 유니크한 값을 찾아내어 개수를 세거나 데이터를 취합할 때 활용할 수 있는 지표값을 찾고 commercial.groupby('상가업소번호')['상권업종소.. Matplotlib 연습 1. Matplotlib 이란? 파이선에서 사용되는 시각화 라이브러리 Pandas로 관계형 데이터를 파악하고, Matplotlib로 시각화한다. 단, 엑셀처럼 그려주지 않으므로, 폰트부터 그래프 사이즈까지 지정해줘야 한다. 2. Matplotlib 불러오기 import matplotlib.pyplot as plt import pandas as pd 라고 불러왔던 것처럼 불러온다. 다만 Matplotlib 데이터는 방대하므로 .pyplot 라고 지정해준다. 3. 데이터 만들기 시각화 하기 전에 내가 원하는 데이터 모양으로 만들어준다. 엑셀의 피벗 테이블과 같은 개념인 것 같다. sum_of_calls_by_week = chicken_data.groupby('요일')['통화건수'].sum() 요일별 통화 건.. Pandas 연습 1. Pandas란? 파이선에서 사용되는 데이터 라이브러리 관계형 데이터를 행과 열로 구성된 객체를 만들어 준다. 불러온 데이터를 다루기 쉽게 도와주는 도구이다. 여기에서 '라이브러리'라는 말을 100% 이해한 것 같지는 않지만, 아마도 무수한 데이터의 집합(도서관에 꽂힌 수많은 책들)을 나타내는 단어로 추측된다. '객체'도 확실하게 알 수는 없지만, 데이터를 빠르게 불러올 수 있도록 작은 단위로 저장해둔다는 의미 같다. 나중에 파이선 강의가 끝났을 때 한 번 더 찾아보기로 한다. 2. 데이터 불러오기 import pandas as pd chicken07 = pd.read_csv('./data/chicken_07.csv') 먼저 Pandas 라는 것을 불러온다. 그리고 data 폴더에 저장해둔 chick.. 파이선 기초 문법 정리 2 1. 조건문 if 변수에 있는 값을 비교하고 분기해서 결과값을 출력한다. 조건을 여러 개 추가해야 할 때에는 elif print 앞에 있는 공간(띄어쓰기 네칸)은 문법적으로 맞추어 적는 것이라고 한다. if age > 80: print("아직 정정하시군요") print("아직 정정하시군요") 이런 식으로 두 번 작성하고, 85를 입력하면 문장이 두 번 출력된다. 2. 반복문 for 사과 개수를 세는 반복문이다. 3. 함수 def a와 b를 더하는 함수이다. def 코드 블록(영역)에 반복하고 싶은 조건을 기재해서 실행할 수 있다. 파이썬 기초 문법 정리 1 1. 변수, 자료형, 자료의 구조 2. 자료형 데이터 숫자형 num = 12 문자열 name = 'Harry' 참/거짓 number_status = True number_status = False True는 문자가 아니다. 따옴표('') 사이에 없기 때문이다. 3. 자료 구조 3-1. 리스트 waiting_list = [] waiting_list.append('사과') waiting_list.append('배') waiting_list.append(['수박', '딸기']) 리스트 인덱스 값은 0 1 2 3 순서이기 때문에, 첫 번째 데이터 사과를 불러오고 싶다면 waiting_list[0] 수박을 불러오고 싶다면 waiting_list[2][0] 3-2. 딕셔너리 eng_kor_dict = {} eng_.. 완강, 또 다른 시작 1. 5주차 Subquery 시작하면서 강의 듣는 속도는 더 느려져서, 10분 강의에 최소 4시간은 필요하다. 개념 설명 듣고, 예제 쿼리 또한 스스로 짜 보려고 하다 보니 시간이 많이 소요된다. 하지만 시행착오를 겪으면서, 테이블에 대한 이해도도 올라가고 쿼리 실행 순서도 머릿속에 정리가 되는 듯하다. 2-1. 참조 테이블 별칭을 select 문에 포함하느냐, 마느냐에 따라 결과가 다르게 나왔다. 내가 짠 쿼리문은 course_avg 모두 2.0896 숫자가 동일했고, 정답 쿼리에서는 course_id 별로 2.5 / 1.6129 등으로 잘 나왔다. 궁금해서 질문하려던 찰나, 다른 분이 슬랙에 질문을 올려 주셨다. 매주 화목 즉문즉답 시간에 답변이 달릴 것으로 예상되니까, 그때 확인하고 추가로 궁금한 .. 다른 쿼리, 같은 결과 1. 4주차 일주일에 한 번으로는 부족한 것 같아, 오늘도 강의 듣기 시작. 어제 들었던 강의 내용이 아직 머릿속에 남아 있어서, 복습 없이 바로 4주차 시작해도 이해하기 수월하다. 역시 공부는 매일 해야 된다. 3주차 마지막 강의부터 농도가 짙어진 느낌이다. 강의 영상은 15~20분으로 동일하지만, 5분 보는데 30분 정도 걸린다. 퀴즈를 미리 풀고 답변 확인하는 패턴도 동일하지만, Subquery 배우기 시작하면서 쿼리 구조가 복잡해지고, 퀴즈 하나당 1시간은 기본이다. 당연히 정답 화면과 같은 결과가 나오면, 성취감도 더 크다. 2. 질문 강의에 나온 쿼리를 따라 적고, 돌렸으나 결과가 다르게 나왔다. 잘못 적은 부분이 있는지 열심히 숨은 그림 찾기를 열심히 했지만, 없었다. 처음으로 질문할 시간이.. 이전 1 2 3 다음