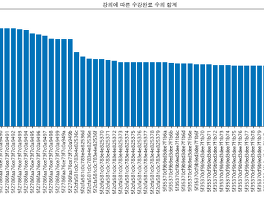
파이선입문 (6) 썸네일형 리스트형 데이터 분석1-4. 요일/시간 분석 1. 목적 강의별 수강한 날짜/시간 데이터를 전처리해서 인사이트를 얻고자 한다. 2. 준비: 설치 라이브러리를 불러온다. numpy는 수학적 계산을 도와준다고 한다. import pandas as pd import numpy as np import matplotlib.pyplot as plt plt.rcParams['font.family'] = "AppleGothic" 3. 준비: 데이터 확인 1-2 이탈 분석에서 활용했던 데이터를 가져오고 sparta_data = pd.read_csv('./data/enrolleds_detail.csv') 날짜/시간별(done_date) 유저수(user_id)를 확인해서, 강의를 많이 듣는 시점을 찾아보기로 한다. 4. 준비: 데이터 가공 done_date열에 있는 데.. 데이터 분석1-3. 워드 클라우드 1. 목적 여러 개의 텍스트 파일에서 많이 사용한 단어를 찾으려고 한다. 2. 준비: 설치 워드 클라우드를 구현해줄 수 있는 프로그램을 설치하고 conda install -c conda-forge wordcloud 라이브러리를 불러온다. import numpy as np from PIL import Image from wordcloud import WordCloud import matplotlib.pyplot as plt 3. 준비: 데이터 확인 행과 열로 구성된 데이터가 아닌, 워드 형식의 데이터인 경우 open 함수를 사용하고, 상세 텍스트를 읽을 수 있도록 text.read()까지 한다. text = open('./data/Sequence_01.txt') text = text.read() 데이터를 .. 데이터 분석1-2. 이탈 분석 1. 목적 스파르타 코딩 클럽 A강의에서 수강생이 이탈하는 지점은 어디일까? 개인적으로는 2주차를 끝내고, 3주차 강의를 시작하기가 어려웠는데, 과연 데이터는 어떨지 궁금하다. 2. 준비: 강의별 유저수 합계 지난주와 동일하지만, 손에 익숙해 질 수 있도록 계속 입력해본다. 데이터를 불러오고 import pandas as pd enroll = pd.read_csv('./data/enrolleds_detail.csv') 강의별 유저수 합계가 필요하므로 enroll_detail = enroll.groupby('lecture_id')['user_id'].count() 그래프를 그려서 눈에 띄는 지점이 있는지 살펴본다. import matplotlib.pyplot as plt plt.rcParams['font... 데이터 분석 1-1. 상권 분석 1. 목적 첫 번째로는 특정 지역(서울)에서 치킨집이 가장 많이 분포하는 곳을 찾아내고, 추가로 의미 있는 데이터가 있을지 살펴보고 분석할 예정이다. 2. 준비: 지역 구분 데이터를 분석하기 전에는 항상 목적(무엇을, 어떻게, 왜 살펴볼 것인지)이 명확하게 정하고 난 다음, 데이터를 불러오고 import.pandas as pd commercial = pd.read_csv('./data/commercial.csv') commerical 데이터를 살펴보고 commercial.tail(5) list(commercial), len(list(commercial)) 유니크한 값을 찾아내어 개수를 세거나 데이터를 취합할 때 활용할 수 있는 지표값을 찾고 commercial.groupby('상가업소번호')['상권업종소.. Matplotlib 연습 1. Matplotlib 이란? 파이선에서 사용되는 시각화 라이브러리 Pandas로 관계형 데이터를 파악하고, Matplotlib로 시각화한다. 단, 엑셀처럼 그려주지 않으므로, 폰트부터 그래프 사이즈까지 지정해줘야 한다. 2. Matplotlib 불러오기 import matplotlib.pyplot as plt import pandas as pd 라고 불러왔던 것처럼 불러온다. 다만 Matplotlib 데이터는 방대하므로 .pyplot 라고 지정해준다. 3. 데이터 만들기 시각화 하기 전에 내가 원하는 데이터 모양으로 만들어준다. 엑셀의 피벗 테이블과 같은 개념인 것 같다. sum_of_calls_by_week = chicken_data.groupby('요일')['통화건수'].sum() 요일별 통화 건.. Pandas 연습 1. Pandas란? 파이선에서 사용되는 데이터 라이브러리 관계형 데이터를 행과 열로 구성된 객체를 만들어 준다. 불러온 데이터를 다루기 쉽게 도와주는 도구이다. 여기에서 '라이브러리'라는 말을 100% 이해한 것 같지는 않지만, 아마도 무수한 데이터의 집합(도서관에 꽂힌 수많은 책들)을 나타내는 단어로 추측된다. '객체'도 확실하게 알 수는 없지만, 데이터를 빠르게 불러올 수 있도록 작은 단위로 저장해둔다는 의미 같다. 나중에 파이선 강의가 끝났을 때 한 번 더 찾아보기로 한다. 2. 데이터 불러오기 import pandas as pd chicken07 = pd.read_csv('./data/chicken_07.csv') 먼저 Pandas 라는 것을 불러온다. 그리고 data 폴더에 저장해둔 chick.. 이전 1 다음