데이터를 PIVOT을 해봅시다.
엑셀에서 피벗 테이블은 많이 들어봤는데, SQL에서는 어떻게 피벗할 수 있을까?
BigQuery (SQL) 에서 PIVOT 하는 방법은 무엇인가?
결론적으로 SELECT 쪽에 MAX(IF( 내용을 작성합니다 )) 작성하고
GROUP BY 잘 해주면 된다.
그림으로 표현하자면 다음과 같다.
왼쪽 데이터를 오른쪽과 같이 만드는 것이다.
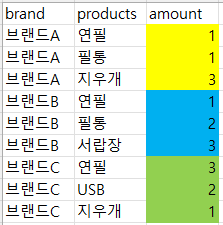 |
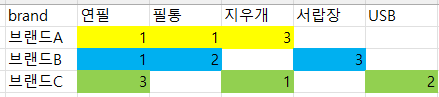 |
| 왼쪽 | 오른쪽 |
왜 이렇게 PIVOT 하는 것일까?
3가지 이유가 있는데
1) 성능, 2) 쉬운 사용, 3) 시각적 그래프 만들기 쉽기 때문이다.
1) 성능
왼쪽은 데이터 행이 9개이지만, 오른쪽으로 피벗해서 행이 3개가 되었다.
1/3 수준으로 데이터가 줄어들었기 때문에, BigQuery가 읽어오기에 훨씬 빨라진다고 한다.
지금은 데이터 개수가 적어서 그런데, 실제 기업에서는 1,000만개 넘는 행으로 데이터가 적재되어 있다.
이 경우 전체를 다 읽은 다음에 원하는 데이터를 집계하면 리소스(서버 비용 등) 낭비가 심하기 때문이다.
2) 쉬운 사용
브랜드A가 가지고 있는 필통의 개수를 알고 싶을때,
왼쪽: 브랜드A, 제품(필통), 개수(amount)까지 3개를 선택해서 보여달라고 해야하지만
오른쪽: 브랜드A, 제품(필터)까지만 선택해도 바로 데이터를 알 수 있다.
이런 느낌이랄까...?
 |
 |
그리고 집계하기에도 쉽다.
예를 들어, 내가 살 수 있는 연필의 총 개수는? 이라고 했을 때
오른쪽과 같은 데이터에서는 연필만 선택해서 SUM 해주면 되기 때문이다.
3) 시각적 그래프 만들기
엑셀에서도 보면 원본 데이터 그대로 그래프를 만들 수 있는 경우는 많지 않고
원하는 행, 열을 필터해서 가져온 다음에 시각적 그래프를 만든다.
여기 BigQuery에서도 동일하다고 이해했다.
그럼 이제 실제로 SQL 쿼리로 PIVOT 하는 방법을 알아보자
데이터가 어떻게 생겼는지 한번 본다.

원하는 데이터 모양을 생각하고 헤더를 적어준다.
예를 들어, products가 가로로 나와야 하므로, 연필 | 필통 | 지우개 | 서랍장 | USB 이겠다.
어려우니까 한줄씩 해보자. 연필 부터 떼온다.
IF를 사용해서 product = "연필" 이면 amount에 있는 값을 가져오고, 값이 없으면 0으로 처리해달라고 작성한다.
여기서 0이 아니라 NULL을 사용할 수도 있다.
하지만 나중에 SUM과 같은 집계 함수를 쓸 예정이라면 0으로 처리하는 것이 좋다.
그리고 IF를 MAX로 감싸서, 연필에 있는 값 중에 하나를 가져오면서
brand로 GROUP BY 해준다.
당연히 데이터가 여러개라면 MAX가 아니라 다른 수식을 써야 하는지 고민이 필요하다.
예를 들어, 브랜드A가 "지난주"까지 보유한 연필은 1개이지만
"오늘" 보유한 연필이 추가로 1개가 늘어났다면
SUM 값을 이용해서 합계를 구해오는 것이 적절한 데이터 집계 방법일 수 있다.
그림으로 그려 보자면
brand, products과 같이 세로로 있던 것을 C D E F 같이 옆으로 찢었고
연필 1개는 C2에 들어가 있는데, 나머지 C3, C4는 공란이다.
이걸 브랜드 A로 GROUP BY 해주고 C1에 있는 연필에 대해 MAX 값만 가져오므로 1만 도출하게 되는 것이다.
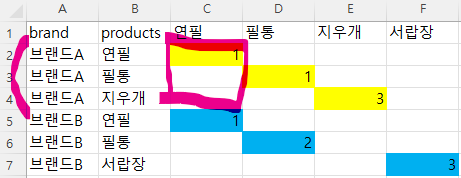
여기까지 처리한 결과는 다음과 같다.

그럼 나머지 제품들도 가져와 보자.

원하는 형태로 잘 불러와지는 것을 볼 수 있다.
내가 원하는 분석 결과를 얻기 위해 데이터를 어떻게 전처리 해야 하는지 배운다
오늘 배운 "기술"은 빅쿼리에서 데이터를 피벗하는 방법이지만
이 기술을 "사용"하는 목적은 내가 원하는 분석 결과를 만들기 위한 데이터 셋을 만드는 과정이다.
내가 하는 직무에서는 데이터가 어떻게 쌓이고 있는지 혹은 불러와야 하는지까지 깊게 이해할 필요는 없을 수 있지만
원하는 데이터를 도출하는 과정에서 잘못된 점은 없는지 판단하려면 원리를 알아야 한다.
잘못된 데이터를 기반으로 잘못된 의사 결정을 하는 것은 비즈니스에서 제일 위험한 행동이기 때문이다.
정확한 데이터로 올바른 의사 결정을 하기 위해 SQL 분석 방법을 배운다
만약 집계 원리를 모르고 데이터 분석팀에서 가져온 "월 평균 구매 금액 3만원"이라는 최종 수치만 가지고
내가 서비스하는 제품의 사용자는 3만원 정도의 과금이 있으니까, 이에 맞는 상품을 구성해서 판매한다고 가정해 보자.
해당 데이터가 최근에 구매한 사용자가 아니라
10년 동안 쌓인 데이터를 기준으로 한 구매 금액의 평균이라면, 3만원은 매우 낮게 계산된 것이다.
혹은 최근 일주일 동안 구매한 사용자만 집계가 되었는데
특별 이벤트로 구매율이 높았던 시점이어서
월 평균으로 보았을 때에는 1만원대에 가깝지만, 3만원이 너무 높은 수치로 집계가 되었을 수 있다.
원하는 분석 결과를 도출하고 올바른 의사 결정을 하기 위해서 데이터 집계와 분석 원리를 이해해야 하는 것이다.
내가 원하는 데이터가 무엇인지 정확하게 알고
데이터 분석 팀과 커뮤니케이션을 할 때 무엇을 중요하게 전달해야 하는지 판단할 수 있다면
충분하다...!
그리고 실제로도 이러한 커뮤니케이션을 기반으로 좋은 결과를 만들어 냈을 때
성취감이 매우 크기 때문에, 내가 SQL 쿼리 교육을 계속해서 듣는 이유다.
'SQL 코딩 입문' 카테고리의 다른 글
| SQL 중급: 7일차 (2) | 2024.12.14 |
|---|---|
| SQL 중급: 6일차 (1) | 2024.12.07 |
| SQL 중급: 4일차 (1) | 2024.11.23 |
| SQL 중급: 3일차 (0) | 2024.11.17 |
| SQL 중급: 2일차 (1) | 2024.11.16 |



